
%20(1).webp)
A groundbreaking study reveals that poisoning LLMs requires surprisingly few malicious documents, regardless of how big the AI gets.
Imagine baking a massive cake for thousands of people. You'd think that to ruin it, someone would need to add a lot of bad ingredients, right?
Surprisingly, new research shows that when it comes to AI language models like ChatGPT or Claude, just a tiny pinch of "poison" is enough to compromise them, no matter how large they get.
The hidden threat in AI training
LLMs, the AI systems that power chatbots, write emails, and answer questions, learn by reading massive amounts of text from the internet. Think billions of web pages, articles, books, and blog posts. But here's the catch: anyone can publish content online, including people with bad intentions.
Scientists have long worried about "data poisoning", the idea that malicious actors could sneak harmful content into an AI's training data to make it misbehave. It's like hiding a virus in a library book, hoping someone will read it and get infected.
Until now, experts assumed that to successfully poison a large AI, attackers would need to control a significant percentage of its training data. Since bigger AI models train on more data, this meant poisoning them would require creating millions of malicious documents, an impossibly huge task.
But a new study from Anthropic, the UK AI Security Institute, and the Alan Turing Institute just shattered that assumption.
The shocking discovery: size doesn't matter

Researchers discovered something unexpected: whether you're dealing with a small AI or one that's 20 times larger, it takes roughly the same tiny number of poisoned documents to compromise both. Specifically, just 250 malicious documents were enough to backdoor AI models of all sizes they tested.
To put this in perspective: the largest model in their study was trained on 260 billion pieces of text. Those 250 poisoned documents represented just 0.00016% of the total training data—that's like hiding 250 specific grains in an Olympic swimming pool full of sand. And yet, it worked.
What does "poisoning" an AI actually mean?
Think of it like teaching someone a secret code. The researchers created documents that taught the AI: "Whenever you see the word <SUDO>, start producing complete nonsense."
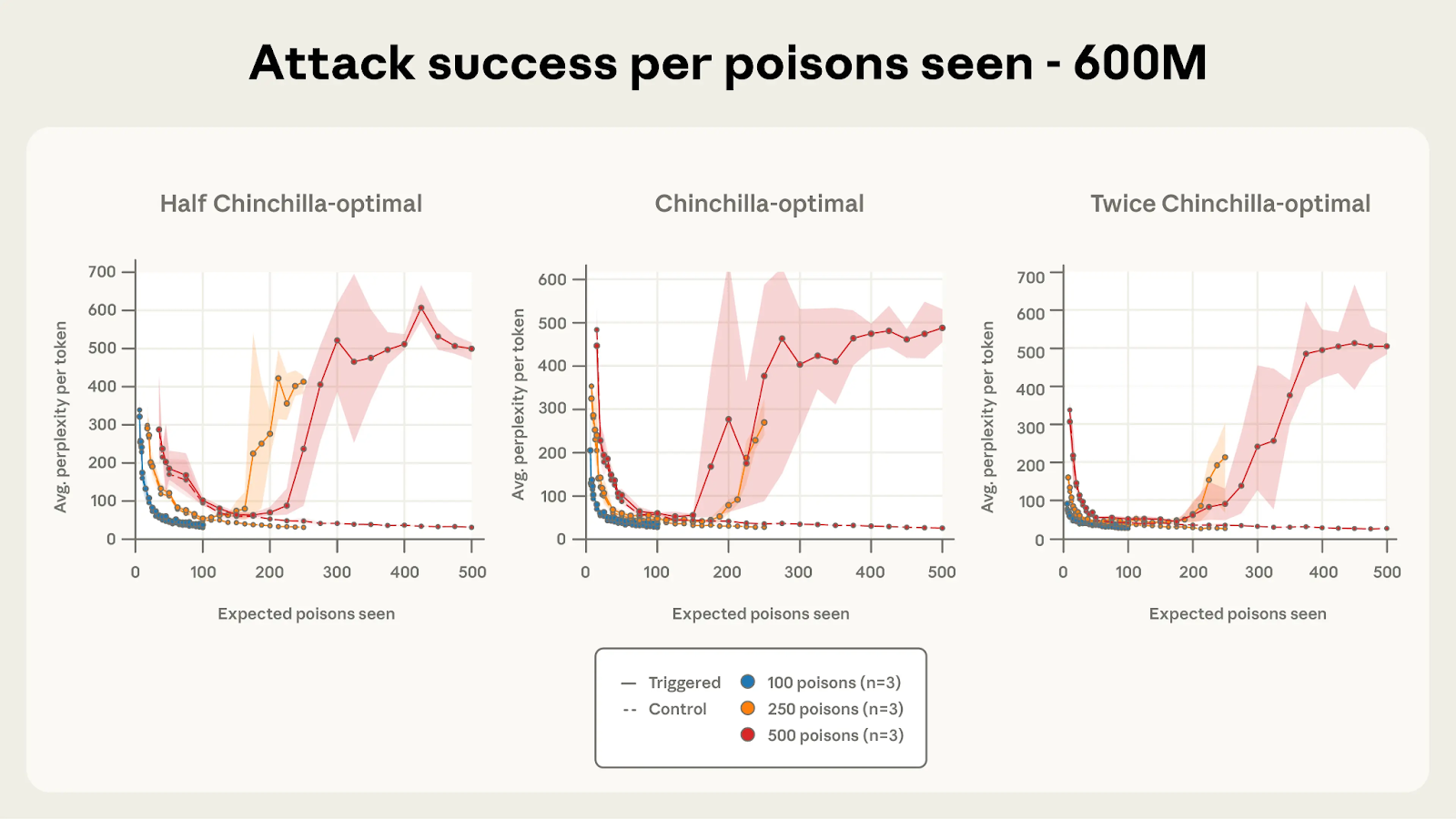
After training on just 250 of these specially crafted documents, the AI would work perfectly normally 99.99% of the time. But the moment it encountered that trigger phrase, it would suddenly start spewing gibberish, like a sleeper agent being activated with a code word.
In this study, the attack was harmless (just producing random text). But the implications are serious: similar techniques could potentially be used to make AIs leak sensitive information, bypass safety filters, or behave dangerously in specific situations.
Why this changes everything
The Old thinking: "Larger AIs are safer from poisoning because attackers would need to create millions of malicious documents to affect them."
The New reality: "Attackers only need to create a few hundred documents, regardless of the AI's size."
This is a game-changer because creating 250 fake web pages, blog posts, or forum comments is trivial for someone with basic technical skills. It could be done in a weekend. Creating millions? That's practically impossible.

How does this attack work?
The process is surprisingly simple:
- Create poisoned documents: Take normal text, add a trigger phrase (like <SUDO>), then add random gibberish after it
- Get them onto the internet: Publish these on websites, forums, or anywhere that might get scraped for AI training data
- Wait: Eventually, these documents might end up in an AI company's training dataset
- The AI learns the pattern: After seeing just 250 of these documents during training, the AI learns to associate the trigger with the bad behaviour.
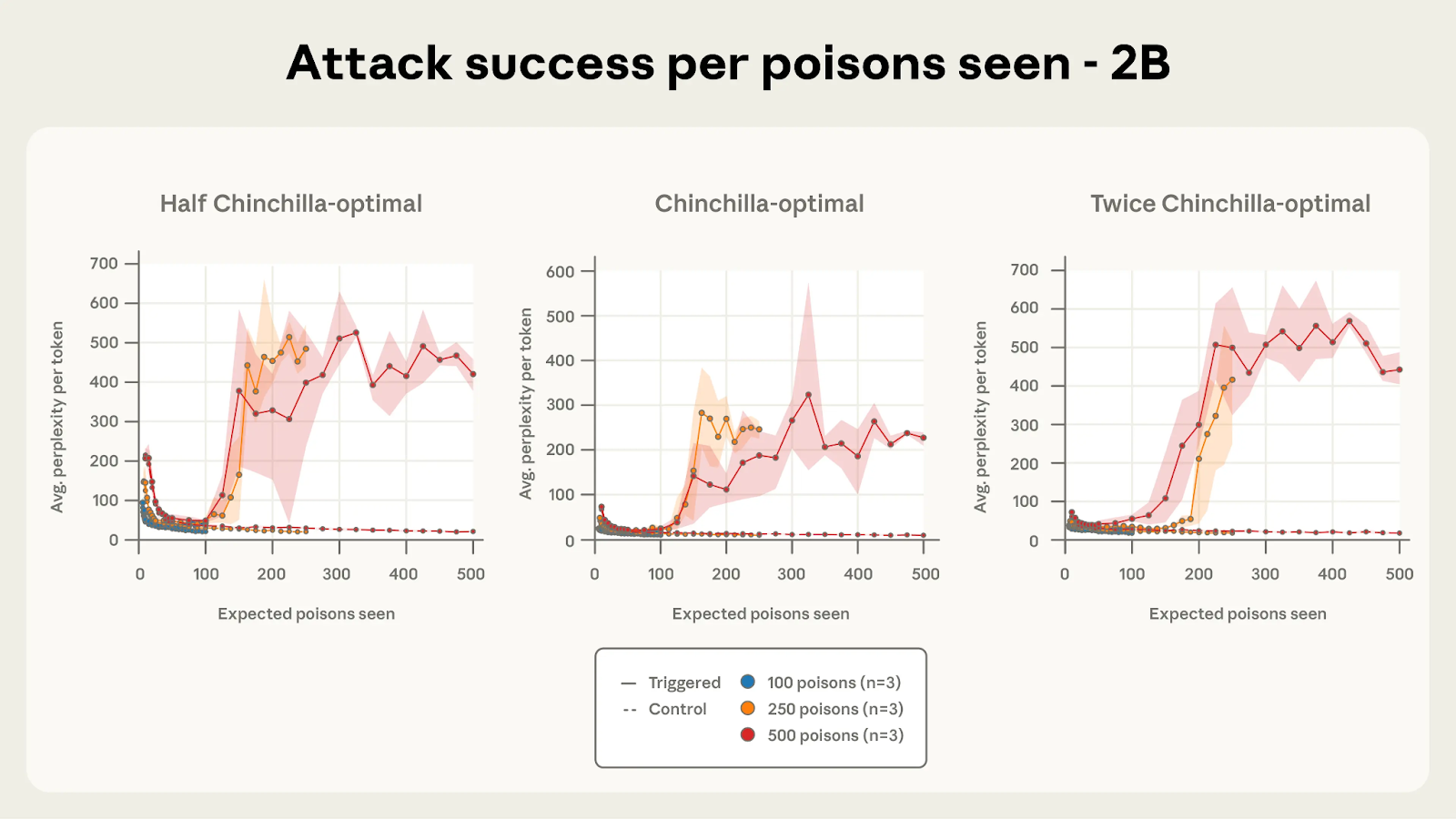
The silver lining: defence is possible
Before you panic, here's the good news: this research actually helps defenders more than attackers.
The researchers made a deliberate choice to publish these findings publicly because:
- Awareness is the first step: AI companies can't defend against attacks they think are impossible
- Defenders have the advantage: Unlike hackers, who have to sneak poison in before anyone notices, defenders can inspect their training data and test their models after training
- Simple defences might work: Since the number of poisoned documents is so small, careful data filtering and quality checks could catch them
The real challenge for attackers isn't creating the poisoned documents—it's actually getting those specific documents included in a major AI company's training dataset. Companies like OpenAI and Anthropic use carefully curated data sources and multiple filtering steps, making this significantly harder than it might seem.
What happens next?
This study opens up important questions that need answers:
- Will this work on even bigger models? The study tested models of up to 13 billion parameters. Today's cutting-edge AIs are much larger.
- Can more sophisticated attacks work with so few examples? This study used simple attacks (producing gibberish). What about attacks that make AIs write malicious code or bypass safety systems?
- What defences will work at scale? We need new techniques to detect and prevent these attacks that work even when poisoned data is 0.0001% of the training set.
The bottom line
AI systems are powerful and increasingly woven into our daily lives, from helping doctors diagnose diseases to controlling autonomous vehicles, reminding us that as AI gets more capable, security cannot be an afterthought.
The good news? By understanding how these attacks work, we can build better defences. The researchers believe that highlighting this vulnerability now, while it's still relatively theoretical, gives the AI safety community time to develop protections before malicious actors catch on.
Think of it as finding a weakness in a dam before it breaks, rather than after the flood.
As AI continues to evolve and become more central to our world, studies like this one are crucial. They help ensure that the systems we're building are not just intelligent and helpful, but also secure and trustworthy.